信通学院学子在⌒计算机视觉领域顶级会议ECCV发表论文
近日,计算机视觉顶级会议ECCV 2020公布收录结果。信通学院智能视觉信息处理团队硕士一年级学生阳隆荣的论文《Learning with Noisy Class Label for Instance Segmentation》成功入选,阳隆荣为论文第一作者,李宏亮教授为通讯作者,电子科技大学为唯一作者单位。学院2016级本科生钱宇阳在商汤科技研究院进行科研实习期间撰写的论文《Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues》也成功入选该¤会议,钱宇阳为论文第一作者,电子科技大学为第一作者单位。
欧洲计算机视觉会议(European Conference on Computer Vision)每两年举办一次,与CVPR、ICCV并称为计算机卐视觉领域的三大顶级会议,受到全世界学术界和工业界的广泛关注。
阳隆荣基于带噪类别标签提供的前景-背景信息始终是正确的这一事实,设计出一种新的组合损失在多实例分割的前景-背景分类的子◥任务中充分地利用带噪的类别标签。多实例分割(instance segmentation)是一项基础且富有挑战性的计算机视觉研究课题,包括前景-背景分类和前景-实例分类两个子任务。在多实例分割中,数据至关重要,然而,类别本身的模糊性或者标记者经验的局限性会导致错误标注的类别标签,这些误标的类别标签会严重恶化模型的精度。此外,分类任务中提出的对噪声鲁棒的对称损失会严重恶化多实例分割中前景-背景分类的精度。具体来说,本文△将一个batch内的样本分】为四类:负样本(NEG)、伪负样本(PSN)、潜在噪声样本(POS)和其他样本(OS)。针对不同的样本,本文提出的方法能够在多个数据库以及多种噪声样本的设置下稳定地提高模型⊙精度,且均优于现有的方法。
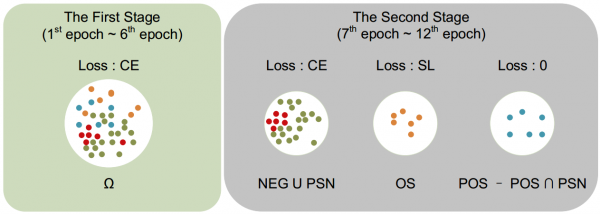
每一个batch内不同样本使用的损失。训练的第二个阶段中,负样本和伪负样本使用交叉熵损失来充分地〗利用带噪类别标签正确的前景-背景信息
近年来,随着人工智能尤其是深度学习的发展,Face Forgery(人脸合成技术)和Deepfake(Deep Learning 和Fake的合成词,即利用机器学习技术进行“换脸”,伪造某人的图像和视频)技术也越来越成熟,可以生成、篡改出@ 更加逼真的人脸。一旦被人恶意利用,后果不堪设想:小到恶搞侵犯他人肖像权利,大到影响政治人物的形象。
为了更加准确地识别出◣这些Deepfake图像视频,钱宇阳同学的工作提出了新颖的Frequency in Face Forgery Network(以下简称F3-Net)。
和先前使用空间域特征(如RGB、HSV特征等)的技术不同,F3-Net更关注图像的频域特征。在低分辨率图像视频中,小范围的人工篡≡改痕迹虽然在RGB空间中难以观察到,但在频域中能很容易地被识别出来。基于这一思路,F3-Net通过挖掘图像中的多种频域特征,更准确地识→别出低分辨率图像的小范围篡改痕迹。
具体而言,F3-Net首先提取了FAD (Frequency-Aware Decomposition) 和LFS (Local Frequency Statistics) 两种频域特征,然→后设计了MixBlock模块,利用cross-attention机制将二者融合并共同进行优化,最终▂输出结果。网络结构如图3所示。
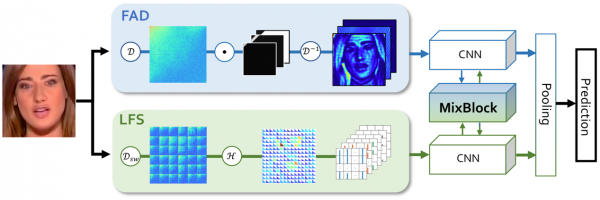
F3-Net的网络结构图
F3-Net从图片中提取得到的两种频域特征(FAD和LFS)是该工作的创新点与核】心所在。在@传统的方法中,人们使用手动设计的固定滤波器提取频域特征,而FAD使用可学滤波器,自适应地对图像频域特征♀进行分解,能够更准确地发现不同频段成分中的伪造痕迹;LFS提取出图像的局部频域统计信息,对细节处的异常更加敏感,且LFS使用滑窗DCT技术,保留了图像的结构信息,使其能够与CNN网络兼容。
实验结♀果表明,F3-Net在FaceForensics++(FF++)数据集上取得了较好的效果,识别准确率比之前的SOTA方法好了约4%。尤其是在经∮过压缩后的低分辨率(Low Quality, LQ)的图像视频中,取得了较︼大的提升。通过挖掘频域特征,F3-Net更准确地让难以分辨的图像视频得以“现形”。
论文链接:
阳隆荣论文:https://github.com/longrongyang/LNCIS
钱宇阳论文:https://arxiv.org/abs/2007.09355
相关链接:
阳∮隆荣自大四起加入李宏亮教授团队,参与多项科研项目,并曾在国家基金委主办的遥感图像智能分析大赛中与团队博士生组队斩获一等№奖(语义分割单元全国第一)。近年来,李宏亮老师率领的智能视觉信息处理团队积极鼓励学生理论联系实际、培养学生求真务实的学风和综合知识运用能力,取得了一系列优异的成绩。
钱宇阳在校期╱间平均GPA 3.98,专业排名前5%。在2018 ACM CCPC中国大学生程序设计竞赛全国邀请赛中获得金牌。荣获2019荣耀通』信年度人物,优秀学生奖学金,优秀本科生毕业论文等奖励。目前已免试推免至南京大学LAMDA实验室继续深造。
未经允许不得转载:二九年华大学门户 » 信通学院学子在计算机视觉领域顶级会议ECCV发表论文
相关推荐
- 格拉斯哥学院举行消防安全知识〓讲座及竞答活动
- 杨元杰课题组研究成果入选美国物理学会《物理》亮点成果
- 学校党委中心组专题学习党的十九大精神
- 电子学院承办2019成都市科技年会电子分会场暨电子信息产业技术♀交流会
- 学校举行第七届成电论坛学科群主题研讨会
- 数字文化与传媒研究中心获批文化部重大项目“中国史诗百部工程”子课题
- 重庆市政协考察团来校调研
- 曹蔚:飒!这个敢想敢做的成电女孩
- 学校召开一站式服务大厅一期总结暨二期启动会
- 校领导专题调研清水河幼儿园建设工作
- 我校科技成果助力科技部《全球生态环境遥感监测2019年度报告》
- 2019年中国高校航空航天类专业“金课”建设研讨会在我校举行
- 校工会获四川省首批“十佳”模范职工之家称号
- 聂念胜:基层々更加需要我!
- 中共中央 国务院印发《新时代∞爱国主义教育实施纲要》
- 重庆理工大学来校调研中外合作办学
- 机电学院走访慰问老同志
- 【天下成电人】朱键:抚平学术与技术之间的鸿沟
- 学校卐研讨部署继续教育工作
- 刘明侦教授团队在《先进科学》上发表研究成果
新闻公告
- 学校党委理论学习中心组召开集体学习会议 08-17
- 资环学院王华教授英文专著由施普林格集团出版 08-17
- 成都市党政代表团来校访问 08-14
- 学校召开学生口学生返校工作会 08-14
- 电子科大2020年第一封本科录取通知书寄出 08-13
- 继续教育学院接受自考网上评卷巡视检查 08-13
- 经管学院赴成都东部新区走访交流 08-13
高考招生
- 电子科技大学2018全日制普通本科招生章程 08-05
- 电子科技大学2016全日制普通本科招生章程 08-05
- 电子科技大学2017全日制普通本科招生章程 08-05
- 电子科技大学2014年全日制▓普通本科招生章程 08-05
- 电子科技大学2015年全日制普通本科招生章∩程 08-05
- 格拉斯哥学院2015招生简章 08-05
- 电子科技大学2013年全日制普通本科招生章程 08-05
- 电子科技大学2011年全日制普通本科招生章程 08-05
- 电子科技大学2012年全日制普通本科招生章程 08-05
- 电子科技大学2008年招生章程 08-05